No Magic: Regular Expressions
This post is part 1 part of a 3 part series.
The code from this post, as well as the post itself, are on github.
Until recently, regular expressions seemed magical to me. I never understood how you could determine if a string matched a given regular expression. Now I know! Here’s how I implemented a basic regular expression engine in under 200 lines of code.
The Spec #
Implementing full regular expressions is rather cumbersome, and worse, doesn’t teach you much. The version we’ll implement is just enough to learn without being tedious. Our regular expression language will support:
.: Match any character|: Matchabcorcde+: Match one or more of the previous pattern*: Match 0 or more of the previous pattern(and)for grouping
While this is a small set of options, we’ll still be able to make some cute regexes, like m (t|n| ) | b to match Star Wars subtitles without matching Star Trek ones, or (..)* the set of all even length strings.
The Plan of Attack #
We’ll evaluate regular expressions in 3 phases:
- Parse the regular expression into a syntax tree
- Convert the syntax tree into a state machine
- Evaluate the state machine against our string
We’ll use a state machine called an NFA to evaluate regular expressions (more on that later). At a high level, the NFA will represent our regex. As we consume inputs, we’ll move from state to state in the NFA. If we get to a point where we can’t follow an allowed transition, the regular expression doesn’t match the string.
This approach was originally demonstrated by Ken Thompson, one of the original authors of Unix. In his 1968 CACM paper he outlines the implementation of a text editor and includes this as a regular expression evaluator. The only difference is that his article is written 7094 machine code. Things used to be way more hard core.
This algorithm is a simplification of how non-backtracking engines like RE2 evaluate regular expressions in provably linear time. It’s notably different from the regex engines found in Python and Java that use backtracking. When given certain inputs, they’ll run virtually forever on small strings. Ours will run in O(length(input) * length(expression).
My approach roughly follows the strategy Russ Cox outlines in his excellent blog post.
Representing a Regular Expression #
Lets step back and think about how to represent a regular expression. Before we can hope to evaluate a regular expression, we need to convert it into a data structure the computer can operate on. While strings have a linear structure, regular expressions have a natural hierarchy.
Lets consider the string abc|(c|(de)). If you were to leave it as a string, you’d have to backtrack and jump around as you tried to keep track of the different sets of parenthesis while evaluating the expression. One solution is converting it to a tree, which a computer can easily traverse. For example, b+a would become:

To represent the tree, we’ll want to create a hierarchy of classes. For example, our Or class will need to have two subtrees to represent its two sides. From the spec, there are 4 different regular expression components we’ll need to recognize: +, *, |, and character literals like ., a and b. In addition, we’ll also need to be able to represent when one expression follows another. Here are our classes:
abstract class RegexExpr
// ., a, b
case class Literal(c: Char) extends RegexExpr
// a|b
case class Or(expr1: RegexExpr, expr2: RegexExpr) extends RegexExpr
// ab -> Concat(a,b); abc -> Concat(a, Concat(b, c))
case class Concat(first: RegexExpr, second: RegexExpr) extends RegexExpr
// a*
case class Repeat(expr: RegexExpr) extends RegexExpr
// a+
case class Plus(expr: RegexExpr) extends RegexExpr
Parsing a Regular Expression #
To get from a string to a tree representation, we’ll use conversion process known as “parsing.” I’m not going to talk about building parsers in a high level of detail. Rather, I’ll give just enough to point you in the right direction if you wanted to write your own. Here, I’ll give an overview of how I parsed regular expressions with Scala’s parser combinator library.
Scala’s parser library will let us write a parser by just writing the set of rules that describe our language. It uses a lot of obtuse symbols unfortunately, but I hope you’ll be able to look through the noise to see the gist of what’s happening.
When implementing a parser we need to consider order of operations. Just as “PEMDAS” applies to arithmetic, a different set of rules apply to regular expressions. We can express this more formally with the idea of an operator “binding” to the characters near it. Different operators “bind” with different strengths – as an analogy, * binds more tightly than + in expressions like 5+6*4. In regular expressions, * binds more tightly than |. If we were to represent parsing this as a tree the weakest operators end up on top.
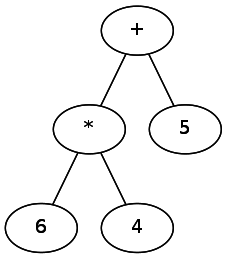
It follows that we should parse the weakest operators first, followed by the stronger operators. When parsing, you can imagine it as extracting an operator, adding it to the tree, then recursing on the remaining 2 parts of the string.
In regular expressions the order of binding strength is:
- Character Literal & parentheses
+and*- “Concatenation” – a is after b
|
Since we have 4 levels of binding strength, we need 4 different types of expressions. We named them (somewhat arbitrarily): lit, lowExpr (+, *), midExpr (concatenation), and highExpr (|). Lets jump into the code. First we’ll make a parser for the most basic level, a single character:
object RegexParser extends RegexParsers {
def charLit: Parser[RegexExpr] = ("""\w""".r | ".") ^^ {
char => Literal(char.head)
}
Lets take a moment to explain the syntax. This defines a parser that will build a RegexExpr. The right hand side says: “Find something that matches \w (any word character) or a period. If you do, turn it into a Literal.
Parentheses must be defined at the lowest level of the parser since they are the strongest binding. However, you need to be able to put anything in parentheses. We can accomplish this with the following code:
def parenExpr: Parser[RegexExpr] = "(" ~> highExpr <~ ")"
def lit: Parser[RegexExpr] = charLit | parenExpr
Here, we’ll define * and +:
def repeat: Parser[RegexExpr] = lit <~ "*"
^^ { case l => Repeat(l) }
def plus: Parser[RegexExpr] = lit <~ "+"
^^ { case p => Plus(p) }
def lowExpr: Parser[RegexExpr] = repeat | plus | lit
Next, we’ll define concatenation, the next level up:
def concat: Parser[RegexExpr] = rep(lowExpr)
^^ { case list => listToConcat(list)}
def midExpr: Parser[RegexExpr] = concat | lowExpr
Finally, we’ll define or:
def or: Parser[RegexExpr] = midExpr ~ "|" ~ midExpr
^^ { case l ~ "|" ~ r => Or(l, r)}
Lastly, we’ll define highExpr. highExpr is an or, the weakest binding operator, or if there isn’t an or, a midExpr.
def highExpr: Parser[RegexExpr] = or | midExpr
Finally, a touch of helper code to finish it off:
def listToConcat(list: List[RegexExpr]): RegexExpr = list match {
case head :: Nil => head
case head :: rest => Concat(head, listToConcat(rest))
}
def apply(input: String): Option[RegexExpr] = {
parseAll(highExpr, input) match {
case Success(result, _) => Some(result)
case failure : NoSuccess => None
}
}
}
That’s it! If you take this Scala code you’ll be able to generate parse trees for any regular expression that meets the spec. The resulting data structures will be trees.
Now that we can convert our regular expressions into syntax trees, we’re well underway to being able to evaluate them. I wrote about the next steps in part 2. As always, the code is on Github.