No Magic: Regular Expressions, Part 3
Evaluating the NFA #
In part 1, we parsed the regular expression into an abstract syntax tree. In part 2, we converted that syntax tree into an NFA. Now it’s time evaluate that NFA against a potential string.
NFAs, DFAs and Regular Expressions #
Recall from part 2 that there are two types of finite automata: deterministic and non-deterministic. They have one key difference: A non-deterministic finite automata can have multiple paths out of the same node for the same token as well as paths that can be pursued without consuming input. In expressiveness (often referred to as “power”), NFAs, DFAs and regular expressions are all equivalent. This means if you can express a rule or pattern, (eg. strings of even length), with an NFA, you can also express it with a DFA or a regular expression. Lets first consider a regular expression abc* expressed as a DFA:
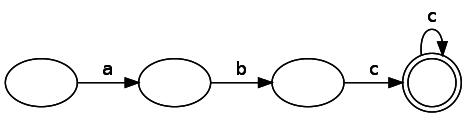
Evaluating a DFA is straightforward: simply move through the states by consuming the input string. If you finish consuming input in the match state, match, otherwise, don’t. Our state machine, on the other hand, is an NFA. The NFA our code generates for this regular expression is:
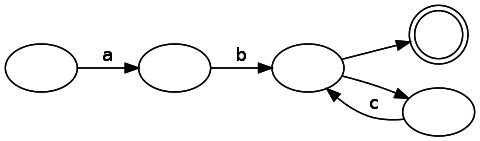
Note that there are multiple unlabeled edges that we can follow without consuming a character. How can we track that efficiently? The answer is surprisingly simple: instead of tracking only one possible state, keep a list of states that the engine is currently in. When you encounter a fork, take both paths (turning one state into two). When a state lacks a valid transition for the current input, remove it from the list.
There are 2 subtleties we have to consider: avoiding infinite loops in the graph and handling no-input-transitions properly. When we are evaluating a given state, we first advance all the states to enumerate all the possible states reachable from our current state if we don’t consume any more input. This is the phase that also requires care to maintain a “visited set” to avoid infinitely looping in our graph. Once we have enumerated those states, we consume the next token of input, either advancing those states or removing them from our set.
object NFAEvaluator {
def evaluate(nfa: State, input: String): Boolean =
evaluate(Set(nfa), input)
def evaluate(nfas: Set[State], input: String): Boolean = {
input match {
case "" =>
evaluateStates(nfas, None).exists(_ == Match())
case string =>
evaluate(
evaluateStates(nfas, input.headOption),
string.tail
)
}
}
def evaluateStates(nfas: Set[State],
input: Option[Char]): Set[State] = {
val visitedStates = mutable.Set[State]()
nfas.flatMap { state =>
evaluateState(state, input, visitedStates)
}
}
def evaluateState(currentState: State, input: Option[Char],
visitedStates: mutable.Set[State]): Set[State] = {
if (visitedStates contains currentState) {
Set()
} else {
visitedStates.add(currentState)
currentState match {
case placeholder: Placeholder =>
evaluateState(
placeholder.pointingTo,
input,
visitedStates
)
case consume: Consume =>
if (Some(consume.c) == input
|| consume.c == '.') {
Set(consume.out)
} else {
Set()
}
case s: Split =>
evaluateState(s.out1, input, visitedStates) ++
evaluateState(s.out2, input, visitedStates)
case m: Match =>
if (input.isDefined) Set() else Set(Match())
}
}
}
}
And that’s it!
Put a bow on it #
We’ve finished all the important code, but the API isn’t as clean as we’d like. Now, we need to create a single-call user interface to call our regular expression engine. We’ll also add the ability to match your pattern anywhere in the string with a bit of syntactic sugar.
object Regex {
def fullMatch(input: String, pattern: String) = {
val parsed = RegexParser(pattern).getOrElse(
throw new RuntimeException("Failed to parse regex")
)
val nfa = NFA.regexToNFA(parsed)
NFAEvaluator.evaluate(nfa, input)
}
def matchAnywhere(input: String, pattern: String) =
fullMatch(input, ".*" + pattern + ".*")
}
To use it:
Regex.fullMatch("aaaaab", "a*b") // True
Regex.fullMatch("aaaabc", "a*b") // False
Regex.matchAnywhere("abcde", "cde") // True
That’s all there is to it. A semi-functional regex implementation in just 106 lines. There are a number of things that could be added but I decided they added complexity without enough value:
- Character classes
- Value extraction
?- Escape characters
- Any many more.
I hope this simple implementation helps you understand what’s going on under the hood! It’s worth mentioning that the performance of this evaluator is heinous. Truly terrible. Perhaps in a future post I’ll look into why and talk about ways to optimize it…